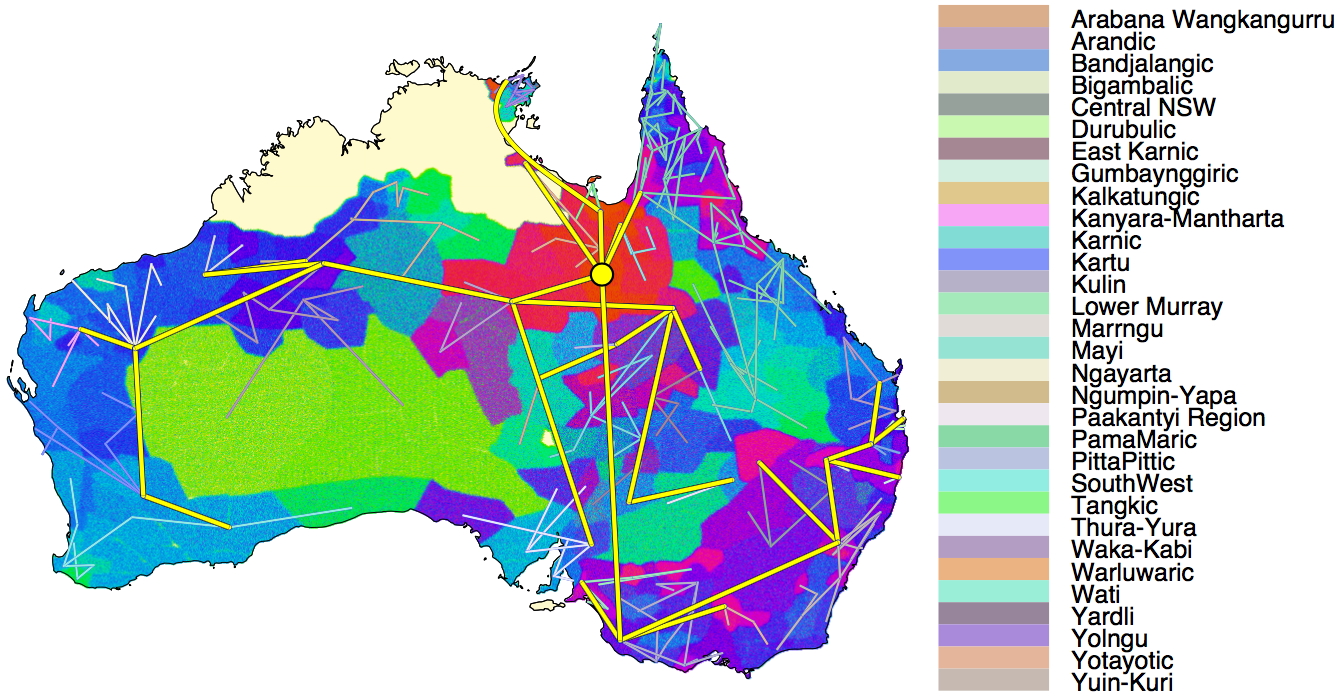
Below is a summary tree, which shows the best-supported relationships within the Pama-Nyungan family, as well as attempting to capture uncertainty in the distribution of trees. There are 306 languages, grouped into 31 sub-families as shown by the labels outside the circle. The colour of the branches is dark grey when there is no movement, and light blue when migration happens at faster rates. Numbers at split points indicate how much posterior support there is for the grouping, but the number is left out when there is 100% support. Note the low support values near the root of the tree, and rather high values near the leaves of the tree. That is, the closer we get to the present, the more confident we are about what the subgrouping is.
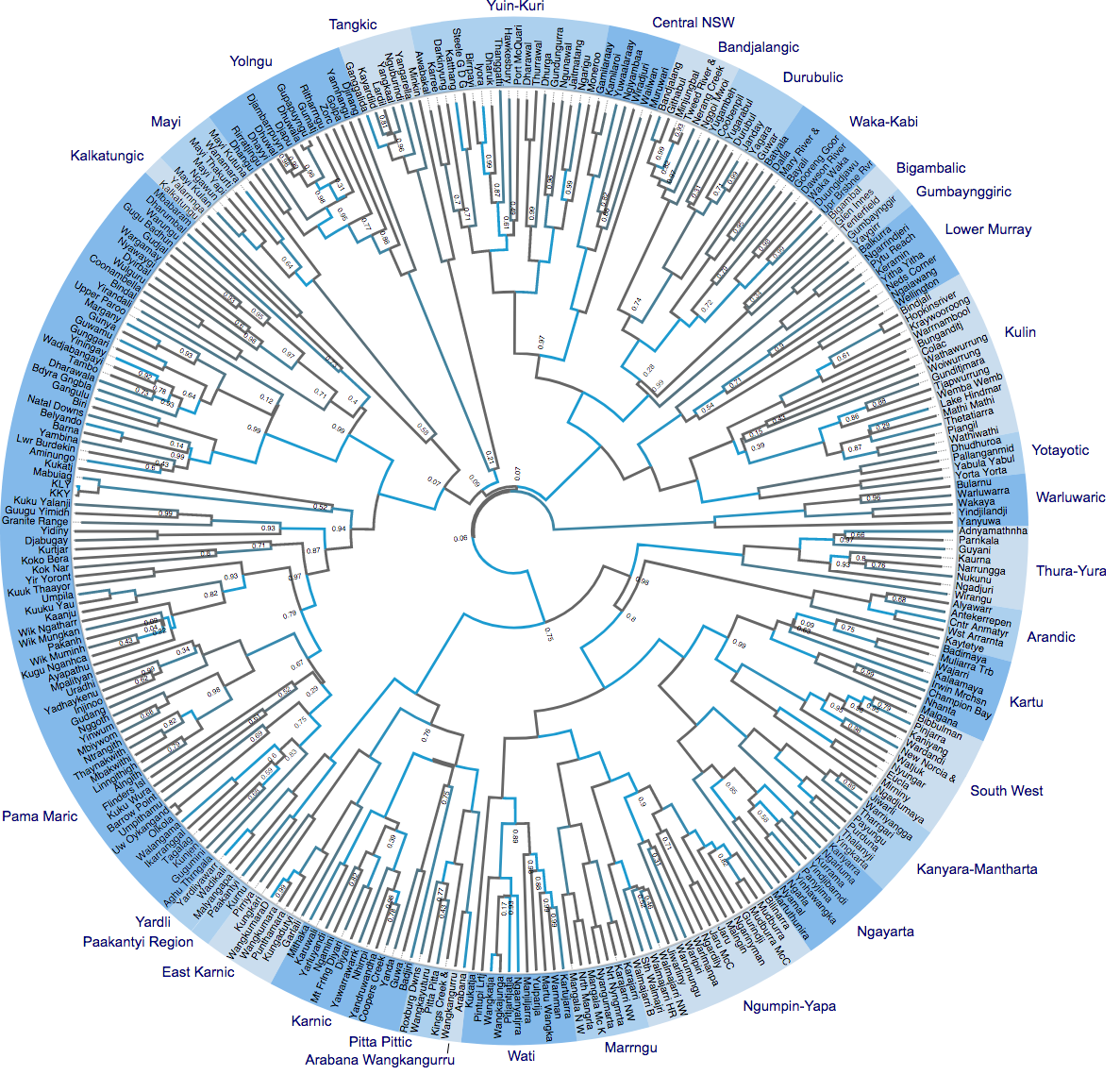
Tracing back down the branches of the tree, we can infer the likely location in time and space of Proto-Pama-Nyungan (the common ancestor of the Pama-Nyungan languages in our sample). This is depicted visually in our Figure 1, below. Most of the points fall in the rapid replacement (red – H1) area, and there is some support for the early Holocene (yellow – H2) hypothesis, but very little support for post ACR (green – H3) and none for initial colonisation (blue – H4) hypothesis. The inferred age of the root of the tree also fits with H1. And when the location and timing information is combined, our analysis finds that the origin of H1 is orders of magnitude more likely than any of the other hypotheses.
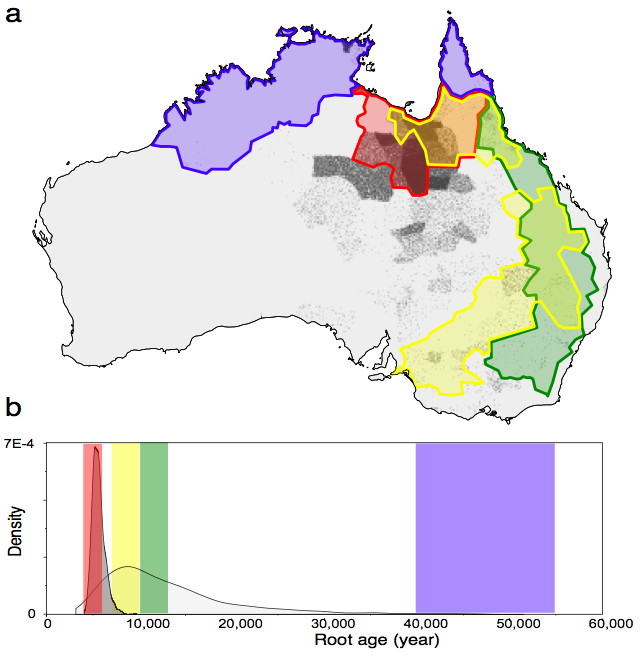
Hence, our analyses support an origin of Pama-Nyungan 5,000 to 7,000 years ago originating from just south of the Gulf of Carpentaria and consistent with the rapid replacement, H1, scenario. in agreement with Hypothesis 1. What can our model say about what happened since that time? The image below allows us to visualise these results.